Кластерная архитектура: Docker Swarm + GlusterFS
Для обеспечения отказоустойчивости необходимо создание кластера из нескольких физических серверов, минимальное количество узлов кластера, обеспечивающих кворум равный трем серверам.
Так же при создание отказоустойчивого кластера предполагается использование одинакового набора жестких дисков для настройки распределённого хранилища обеспечивающего минимальный риск нарушения целостности данных.
Набор сетевых интерфейсов необходимо расчитывать из потребностей данного кластера, но не стоит забывать о необходимых сетевых интерфейсах, которые желательно разделить чтобы технический трафик не мешал потребительскому.
Количество процессоров и количество оперативной памяти рассчитывается из прямого назначения сервера, но в данном расчете должна присутствовать избыточность так как при отказе одного из узлов оставшиеся узлы могли принять на себя сервисы работавшие на отключившимся узле.
Программное обеспечение:
- Centos (основная операционная система)
- GlusterFS (распределённая система хранилища данных, находящиеся на разных серверах)
- Docker Swarm (стандартный оркестратор для docker контейнеров)
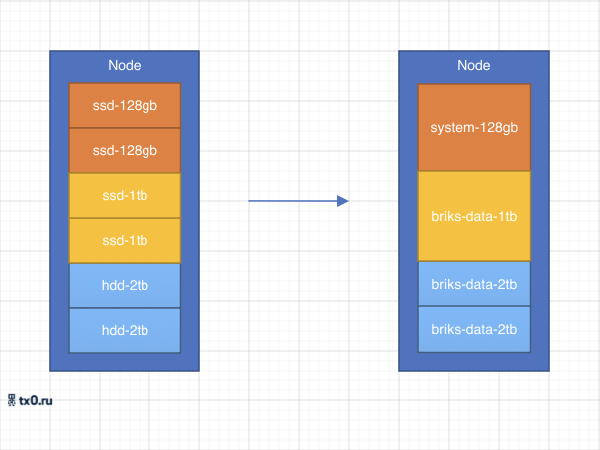
Дисковый массив:
- системные данные: программный рейд состоящий из двух ssd накопителей по 128Гб
- горячие данные: статические данные контейнеров, программный рейд состоящий из двух накопителей по 1-2Тб
- холодные данные: резервные копии, данные тестовых проектов, состоящий из четырех накопителей по 2-3Тб диски подключены в систему как есть
Распределённый массив:
- состоит из массивов горячих данных с избыточным зеркалированием один к трём (Replicated)
- состоит из дисков холодных данных с избыточной репликацией два к трем (Distributed Replicated )
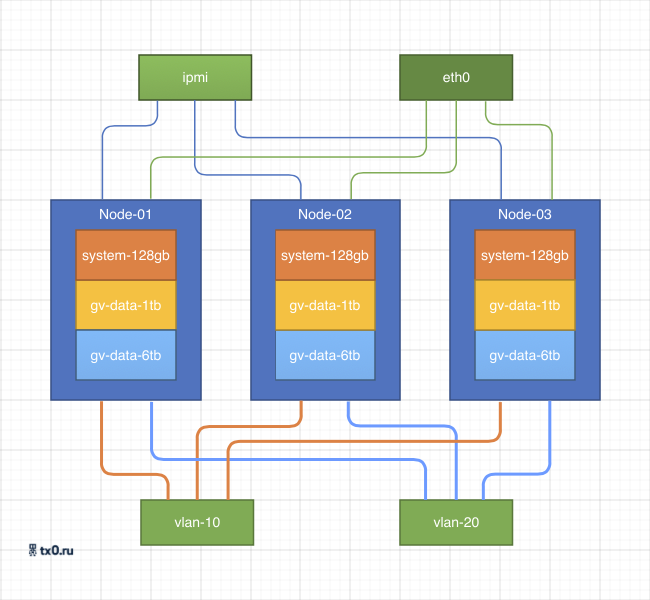
Сетевые интерфейсы:
рекомендуется 4 внешних адреса для распределения по точкам входа в кластер
- внутренние
- ilo/ipmi (интеллектуальный интерфейс управления серверной платформой)
- eth0 (интерфейс управления операционной системой и технический трафик кластера)
- внешние
- eth1:
- vlan интерфейс для публикации сервисов в эксплуатацию
- vlan интерфейс для публикации сервисов в разработку
- eth1:
Не забывайте про внутреннюю красоту старайтесь использовать идентичные названия интерфейсов и дисковых массивов в системе
Роль для всех серверов в Docker Swarm обозначим «manager» и будет оперировать лишь лейблами добавив для каждого сервера тег.
- main
- service
- development
при расчете распределения сервисов в случае обслуживания или отключения одного из узлов не должен превышать зарезервированные ресурсы сервера и должен составлять не более одной третьей от его общей емкости на сервер
Размещение сервисов:
MAIN: предлагается запустить приложения для обслуживания кластера
сервисы обслуживающие кластер могут иметь временые всплески потребления ресурсов так как задействованы в сборке образов для разработки
- VyOS (платформа маршрутизации)
- Traefik (обратный прокси обслуживающий точку входа для администраторов и програмистов)
- FreeIPA (централизованная системы по управлению идентификацией пользователей)
- Teleport (предоставления доступа к серверам и приложениям через SSH)
- Docker Registry (хранение и обмен образами docker)
- Gitlab (систему управления репозиториями кода для Git)
- Gitlab-runner (агент, выполнение инструкций из gitlab)
SERVICE: предлагается запустить сервисы для работы компании
Сервисы компании должны быть описаны и gitlab и запускаться от туда
- Alfresco (управление документами, записями, веб-публикацией, групповой работой и бизнес-процессами)
- Nextcloud (набор клиент-серверных программ для использования совместного хранилища данных)
- Jira (как система управления проектами)
DEVELOPMENT: предлагается запускать приложения разрабатываемые компанией.
Программистам для самостоятельной публикации приложений желательно выделить отдельное пространсво имен в отдельной точке входа для разграничения потребительского трафика.
- Traefik (обратный прокси обслуживающий точку входа для разрабатываемых приложений)
- система хранения резервных копий